


この記事はServerless Advent Calendar 2017の 7日目になります。
Serverlessconf Tokyo 2017で発表させていただく機会をいただき、Java チームが選択した TypeScript による AWS Lambda 開発のタイトルでお話をさせていただきました。
今回はそのシステムの裏手側、CSV ファイルを連携するバッチをサーバーレスで実現したアーキテクチャについてご紹介します。
システム全体の概略図
ざっくりと下図のようなシステムで AWS 上に作られています。
スマートフォンなどから IoT 機器を操作するようなクラウド・サービスがあり、そのバックグラウンド・プラットフォームになります。認証や機器のデータ管理を行うシステムです。
このシステムは、図のAmazon API GatewayとAWS Lambdaが、ペアになっているアイコン毎が1つ1つのマイクロサービスとして作られています。つまり 10を超えるマイクロ・サービスの集合体になります!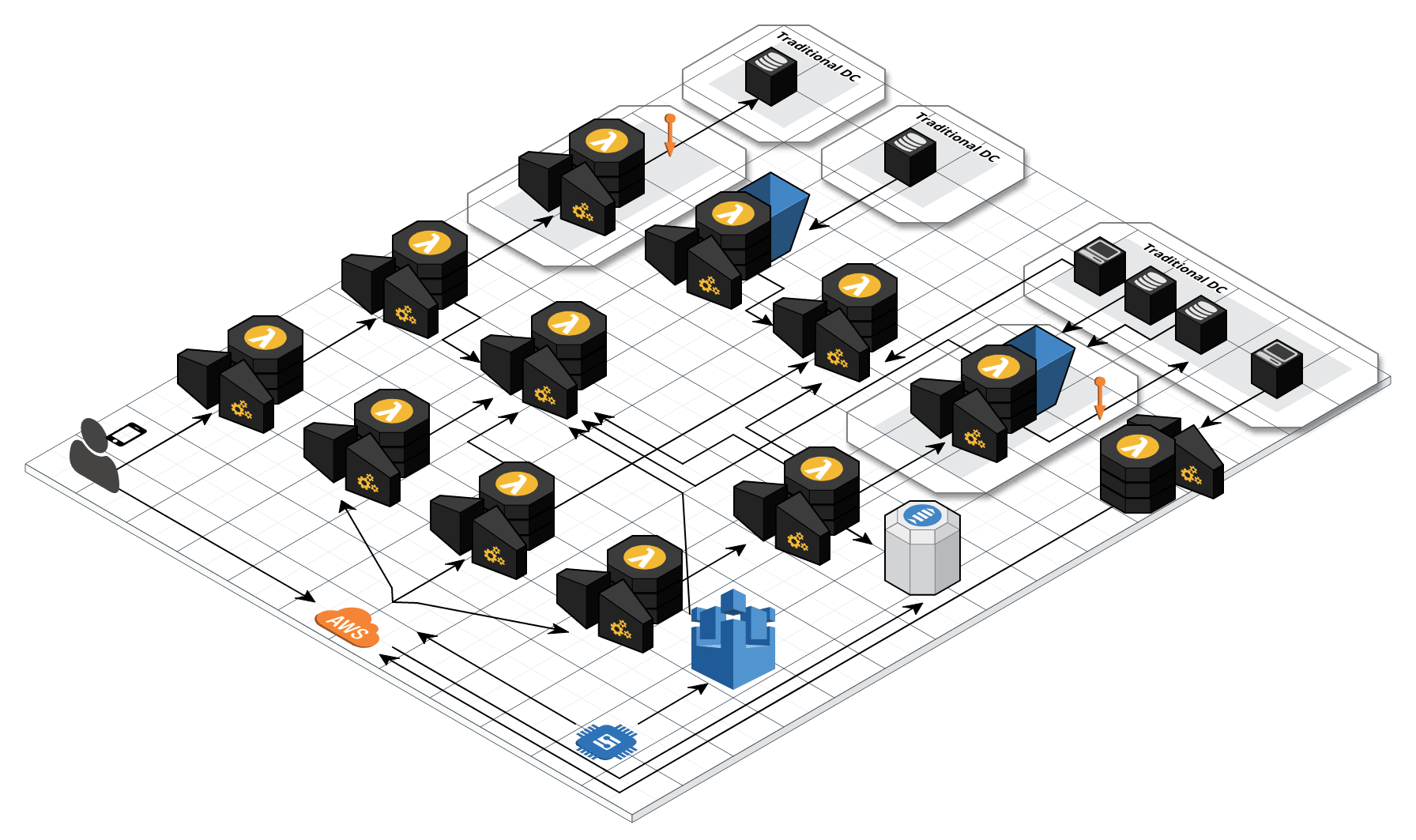
今回の話は、この図の右上部分 “Traditional DC”、企業の伝統的なデータセンターからデータを受ける部分です。
この部分は伝統とシキタリにのっとり CSV ファイルを受け取り、処理する仕組みが必要となります。
※ CSV の C は Comma と信じてましたが、Character や Column 説 (e.g.Wikipedia) があり広義には Comma に限らず特定の文字でデータを区切るファイルらしい。どうでもいいけど。。。
なぜ AWS Lambda ?
このようなシステムを AWS で実装するには、AWS BatchやAWS Glueなどを使います。しかしながら、今回は Lambda で実装することにしました。
背景としては、以下のような点があります。
- 少人数の DevOps チームであり、AWS のマネージド度合いが高いほど嬉しかった
- データ量や処理量から想定してコスパが優れていた
- 1回に連携するデータ量が Lambda の処理時間におさまる可能性が持てた
とくに2番目のコストについては、Glue に対して圧倒的によかったのが大きかったです。今回の処理は ETL に近いとはいえ、DWH 連携ではなく、DB のマスター・データ登録だったので Glue を活かしきれない点がありました。
なお Lambda の実行ランタイムは Java になります。
(Serverlessconf Tokyo 2017 の発表資料の通り、Java チームなので)
CSV ファイル連携のアーキテクチャ概要図
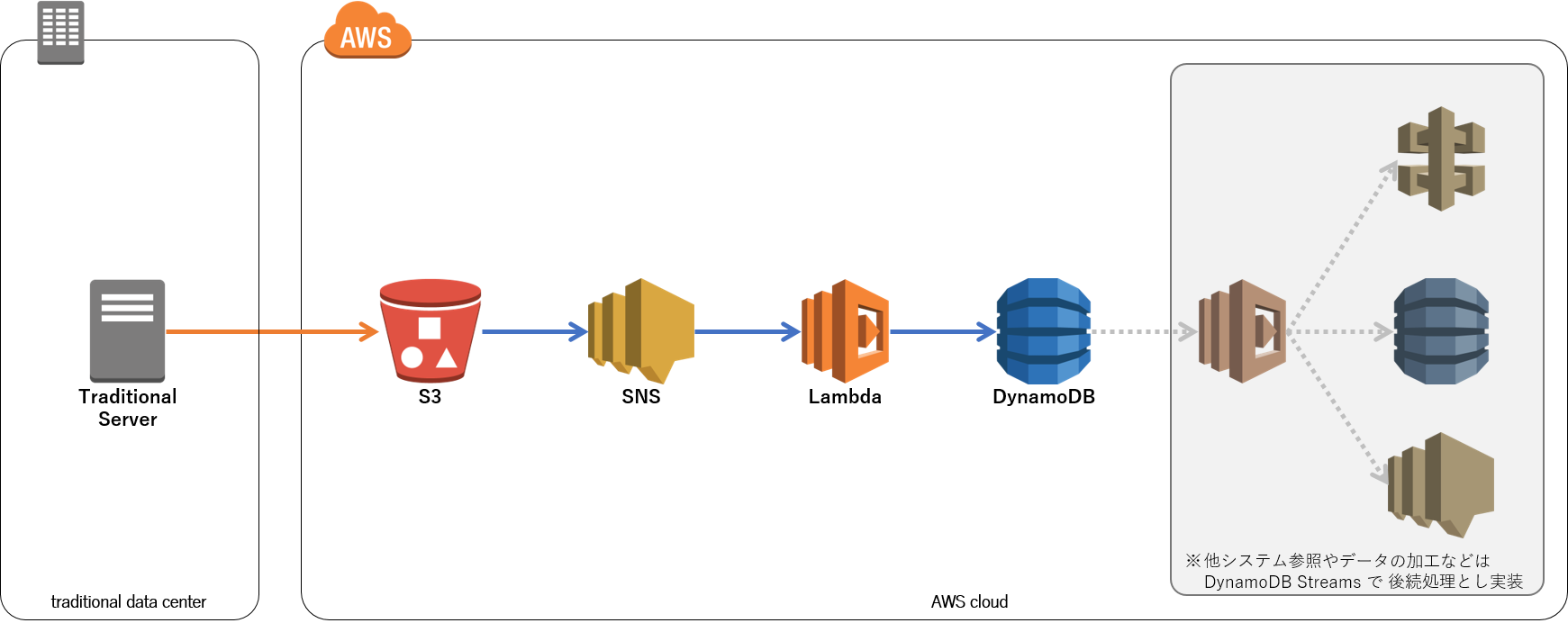
“Traditional DC” からは、Amazon S3に CSV を置いてもらうことにします。FTP/SFTP とのリクエストがありましたが、サーバーレス厨とは言わずとも、ここは S3 へのアップロードへお願いしたいところ、何としてでも承諾いただきます。(いただきました)
S3 からはAmazon SNSへイベント通知をし、Lambda を起動します。その Lambda で CSV をパースして DynamoDB へデータを登録します。
複雑なデータの加工や外部の API/データを参照するような場合は、DynamoDB Streams から Lambda を呼び出して後続の処理として実装します。このようにすることで、データの登録に特化させて処理数を稼ぐことができ、また DynamoDB Streams の後続処理は、登録されたデータ1件ごとの処理になるので時間的な余裕が生まれます。
ここでのポイントは S3 ⇒ SNS からの Lambda は DynamoDB への登録だけに特化し、他の処理をしないことです。このようにすることで、なるべく CSV ファイルの対応に処理を振り分けるようにし、時間内で処理できる量を増やすようにしています。
処理能力とアーキテクチャの改良
このような形にすることで、CSV を Lambda で処理できるようになります。
このアーキテクチャの処理能力は、CSV ファイル 1行のデータ量や、カラム数によって変わってくる部分がありますが、今回のケースでは 1ファイルで約 800行のレコードが処理できました!
て、まったく処理できてません。。。
これでは役に立たないので対応が必要となります。
Lambda は設定するメモリの使用量によって処理速度が変わるという話もあり、最大に設定してみましたが設定による差はとくにありませんでした。ファイルを読み込みながらの順次処理なので、ここでの処理性能はあまり変わらないのでしょう。また DynamoDB へアクセスするオーバーヘッドも処理性能では大きく変わらないはずです。
では、どうするのか。
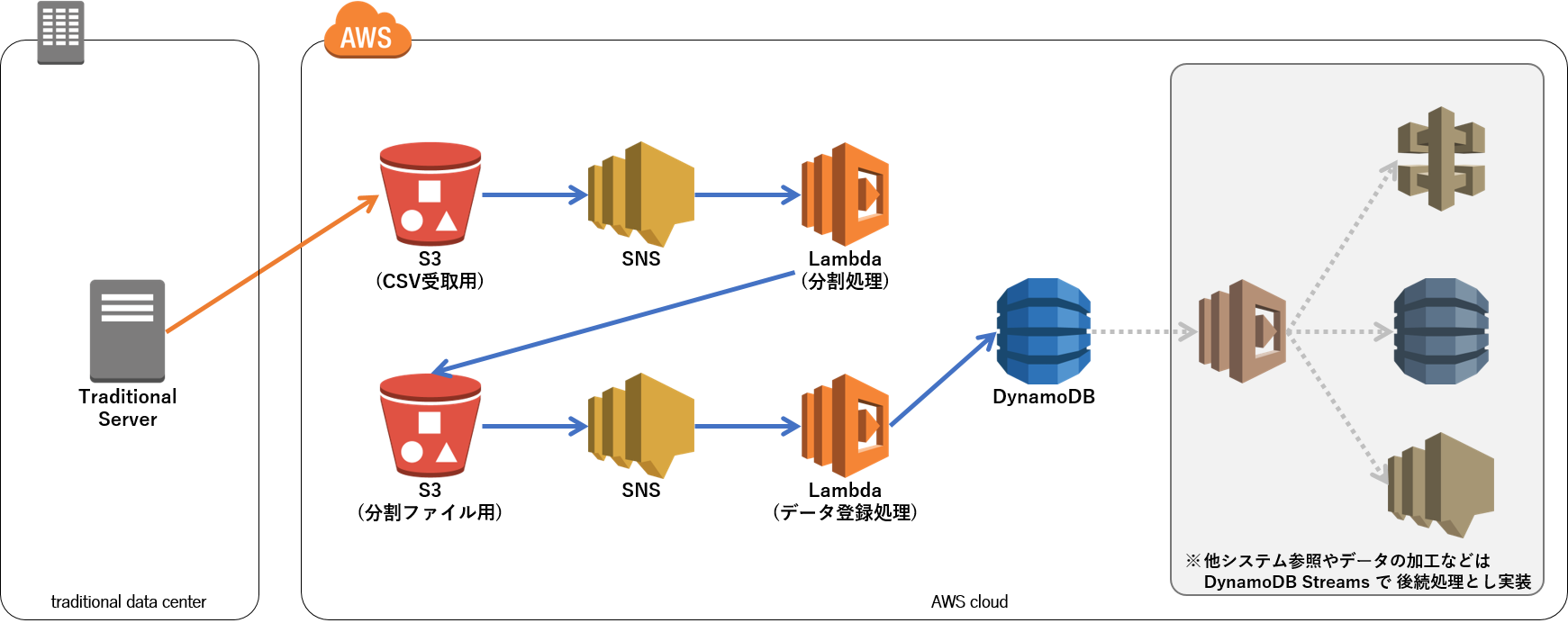
S3 に置かれたファイルを DynamoDB へ登録する前に、ファイル分割する処理をはさみます。
1回の Lambda で DynamoDB へ登録できるのは余裕を見て 500件までとして、CSV ファイルを 500行ごとのファイルに分割して S3 へ再アップロードします。その 500行ごとのファイルを Lambda で DynamoDB へ登録する形にしました。
これにより、30,000行まで処理できるようになり現実的なラインまで持っていけるようになりました。S3 からの Lambda に変わりはないので、サーバーレスの形態も維持できます。
まとめ
サーバーレスでシステムを作ろうとしても、往々にして発生してしまう既存システムとのバッチ連携。そのために FTP/SFTP やら、CSV パースするための処理やらとどうしてもサーバ・インスタンスが欲しくなってしまい、せっかくのサーバーレスがサーバー有り(サーバーレスの反対語って何だろう)になってしまいます。
Glue に見合う処理であればよいのですが、今回のように小規模なデータ登録となるとオーバースペック気味にもなります。そんな時には S3 からの Lambda で処理することで、サーバーレスでバッチ連携をするのも手ではないでしょうか。
ポイントとしては以下になります。
- ファイルは S3 に置いてもらう
- S3 ⇒ SNS から Lambda を起動し DynamoDB へデータ登録に特化する
- 1回の Lambda で処理できるデータ量は少ない、必要に応じてファイル分割の Lambda をはさむ
Serverless Advent Calendar 2017、楽しく、そして勉強になる記事がたくさんです。
昨日6日目は@RyoheiMorimotoさんのAWS LambdaをTest Runnerとして使ってみるでした。 ユーザ管理のシステムをサーバーレスで 34歳タローさんがハナコさんになれるかをテストしています。サーバーレス・テスト、おもしろいですね!
明日8日目は@narikeiさんです。何の記事か楽しみです!
では、ハッピー・サーバーレス・ライフ! ハッピー・ホリデー!!