2019年最後のポスト、1年間の活動を振り返ります。

サマリー
- 発表: 16回
- 記事: 61本
- プルリク: 17本
- アプリ開発: 4本
- ハッカソン: 2回
- Special Topics: 2つ
発表 16回
今年は1月を除いて毎月発表する機会がありました。大きいイベントから勉強会、LT、クローズドの会と多様な場所で話をする機会を頂け、そして多くの出会いに感謝です。ありがとうございます!
去年の6回から、今年は17回と約3倍の発表に臨みました。その中で技術やナレッジを伝えるにあたって話をするのは、私に合った方法なのかなと感じ、引き続き発表の場に立てるよう研鑽して行きたいです。
- Developers Summit 2019にて『サーバーレスで最高に楽しめるアプリ開発」を発表。
- JAWS DAYS 2019にて『AWS x JAMstack で構築・運用するサーバーレスな Web Front』を発表。
- CTO vs Hackers ハッカソンにて『「ミツカルヘアサロン💇」〜個人が提案する時代に向けたアプリ~』を発表。
- Shiftup! JP_Getshifter Vol3にて『JAMstackで構築・運用するサーバーレスなウェブフロント』を発表。
- SPAJAM 2019 東京A予選にて『パーソナルニュースの配信と交換によって爆速で仲良くなるアプリ「📰NEWʑ Link」』を発表。
- Serverless Meetup Tokyo #12にて『サーバーレスなウェブフロントを実現する JAMstack』を発表。
- 初夏のJavaScript祭 in メンバーズキャリアにて『Gridsome で作る JAMstack な サーバーレス Web Front』を発表。
- 勤怠を自動化する技術 LT Nightにて『Web-NFC の PWA で 簡単タイムレコーダー「ツカエタルヒの記録」』を LT しました。
- CloudNative Days Tokyo 2019にて『サーバレス・ネイティブ が お伝えするフルサーバレス開発の魅力!』を発表。
- Shiftup! JP_Getshifter Vol5にて『Shifter+SSG(Static Site Generator) が生み出す、新しい WordPress の世界』を発表。
- クローズドな New Biz アイデアソンにて『1分間のショートピッチ』を2回しました。
- クローズドなサーバーレス勉強会で『ログのトレーサビリティ』について発表をしました。
- WordCamp Tokyo 2019にて『WordPress と SSG が 織りなす WordPress ウェブフロントの新世界』を発表。
- プロポーザルの書き方を学ぼう- 登壇の技術を勉強する会にて『個人やサークルとして応募する CfP、あるいは その思い切り』を発表。
- クローズドなウェブフロント勉強会にて『JAMstack/PWA アーキテクチャの紹介』の発表をしました。
- PWA Night vol.11 ~PWA × CMS~にて『WordPress と SSG で作る、情報発信サイト の JAMstack な PWA』を発表。
1つ1つが大きな思い出がありスライド埋め込みやサマリーを書きたいですが、書ききれなそうなのでいくつかをピックアップしてサマリーします。
年初よりデブサミで発表できたのがスゴイ経験になりました。300 席の会場で立ち見という状況、集客率ランキング 15位と多くの方に関心を持っていただけ嬉しいです。これだ多くの方の前で話をしたのは初めてでした。そして多くの方にサーバーレスでの開発の楽しさをお伝えできてよかったです。いつかまたデブサミの場に立ち、今度は満足度ランキングに載れるような良い発表をできるように技術を磨きたいです。
そして JAWS DAYS 2019。普段 AWS を使って開発をしている中で JAWS DAYS を、はじめとするコミュニティで勉強させて頂いているのを何か返したいとのことで、JAMstack というキーワードが注目を集め始めている中、サーバーレスという観点から JAMstack を取り上げて伝えることができ、コミュニティに少しでも貢献できたのかなと。
また、こちらのイベントでは私の活動を大きく変える転換点となりました。
JAWS DAYS 2019 で Shifter のSeiji Akatsuka(@seijiakatsuka)さんに誘われ Shiftup! JP_Getshifter Vol3 で発表します。
これまでカンファレンスでの発表だけだったので、いわゆる勉強会形式での発表は初めてで、とても緊張しました。しかしながら聞いてくださる方がそばにいて、途中休憩や懇親会で発表前後でカジュアルに参加者さんと話ができる(& 🍺 もある) のが新鮮で、また楽しかったです。このカジュアルな時間から Shifter + SSG のアイデアが生み出され、そして公式神対応という流れが発生します。まさに勉強し新たな世界が作られるのを経験させていただきました。ありがとうございます。
- gridsomeのススメとShifterの可能性について – Photosynthesic blog
- Shiftup! JP_Getshifter Vol3! 振り返り、Shifterのヘッドレス CMS 化に思いを馳せる | Articles | Riotz.works
- ShifterでWebhookによる外部デプロイが可能になりました! - 株式会社デジタルキューブ
そして、その Shiftup! JP_Getshifter Vol3 で様々な出会いが生まれ、Serverless Meetup Tokyo #12、初夏のJavaScript祭 in メンバーズキャリア、WordCamp Tokyo 2019 とつながっていき、今新たなプロジェクトに参画するという大きな変化につながっていきます。人生何があるかわからない。
また初挑戦としては、勤怠を自動化する技術 LT Night で LT にも初挑戦しました。5分、短かっ!見事2分オーバー。すみません。
いろいろ反省する中で、私は話が長いので、もう少し尺の長いものが会うんだろうなぁと思いつつ、一気に話し切る経験は楽しく、また LT に挑戦したいです。
「クローズドな勉強会」が登場するようにもなりました。いろいろな都合により参加者が限られているものですが、話した内容はアウトプット。多くの情報を落とし分かりにくい話にはなってしまいますが、せっかくなので汎化して載せるようにしています。ほぼ作り直しの作業になるので、時間がかかって準備中が取れないものもありますが、可能な限り出したいです。オープンなイベントで話をしたいのはありますが、いろいろな事情があるのでクローズドになるのも仕方なく、そのような場合でも声をかけていただき発表できるのはうれしいので、もしニーズがありましたら声をかけていただけると嬉しいです。
といった発表活動をサマったのが「プロポーザルの書き方を学ぼう- 登壇の技術を勉強する会」。
CfP に、どうやって応募するの、どんな書き方がいいのという話をカンファレンスのオーガナイザーが話をするという面白い勉強会。LT 枠でしたが、後枠が空いてたので 10分いただきトークさせていただきました。ちょうど Riotz.works という活動のサマリーをしたかったので、良い機会になるとともにサークルとしての活動を発信したいという思いもあり、お話しできてよかったです。
そして〆は PWA Night vol.11。もともと PWA 好きで去年の SPAJAM 2018 東京D予選リアルタイムの競演と参加型観戦で音楽を最高に楽しむ「ラップ、タップ、アップ🎶」、今年の SPAJAM 2019 東京A予選パーソナルニュースの配信と交換によって爆速で仲良くなるアプリ「📰NEWʑ Link」とモバイルアプリのハッカソンなのに PWA で戦ってきました。(去年は予選優秀賞を取れたので PWA はスゴイ!)
が、今年の後半は JAMstack を中心に発信し PWA の発信がなくなっていました。そんな中、改めて PWA を思い起こさせていただきました。JAMstack と PWA は相性が良く、来年はセットでしっかり発信していきたいです。
と、怒涛の発表の1年でした。
ちょっとオーバーペースだったので来年はペース配分を考えながらも、発表は私の情報発信方法の中で自分にとって合うので引き続きしっかりと活動していきたいと思います。
あとは似たような方向性としてはハンズオンを作って開催するとかできたらいいなと。
記事 61本
- JAMstack、それはハイパフォーマンスなウェブフロントを実現するアーキテクチャ
- Riots.works での JAMstack の利用
- 発表者は、その日何をしていたのか - 発表の舞台裏 DevSumi 2019 編
- デブサミ 2019 Ask the Speaker にて頂いた QA まとめ
- 発表者は、その日何をしていたのか - 発表の舞台裏 JAWS DAYS 2019 編
- JAWS DAYS 2019 にて頂いた QA まとめ
- デブサミ 2019 にて「サーバーレス開発の楽しさ」について発表をしました
- JAWS DAYS 2019 にて「AWS x JAMstack なサーバーレス Web Front」について発表をしました
- 独自ドメインでメールの送受信できるように、Google Domains のメール転送と Gmail の送信元を設定する
- CTO vs Hackers ハッカソン戦記
- Validate TypeScript にインストールエラーの修正についてのプルリクを送る
- Validate TypeScript による入力データ検証を試す
- TSLint の prefer-function-over-method ルールについて悩む
- 心に刺さる名刺のつくり方セミナー 〜東京編〜 参加レポート
- ブログメンティ始まる
- Shiftup! JP_Getshifter Vol3! 参加レポート
- Shiftup! JP_Getshifter Vol3! にて「JAMstack なサーバーレス・ウェブフロント」について発表をしました
- Shiftup! JP_Getshifter Vol3! 振り返り、Shifterのヘッドレス CMS 化に思いを馳せる
- ブログメンティふりかえり1週目
- ブログで使っている Hexo の SNS 共有リンクに「はてなブックマーク」を追加する
- ブログで使っている Hexo の SNS 共有リンクのユーザビリティを高める
- Google Analytics にプログラムでアクセスできるようにする
- ブログで使っている Hexo に人気の記事リストを表示したい!
- hexo-related-popular-posts にサブパス対応のプルリクを送る
- 「テキスト校正くん」を使って読みやすい文章を書けるようにする
- Asana で個人のタスク管理をする
- ブログメンティふりかえり4週目
- Asana を Google Chrome でアプリウィンドウ化する
- Asana を Nativefier でアプリ化する
- Nuxt.js で PWA(Progressive Web Apps) のベースアプリを作る
- Nuxt.js PWA(Progressive Web Apps) のベースアプリをTypeScript対応する
- Nuxt.js PWA のベースアプリを GitHub Pages へデプロイする
- TypeScript プロジェクト用サンドボックスで簡単コード検証
- SPAJAM 2019 東京A予選 - ハッカソン戦記
- ブログで使っている Hexo の SNS 共有リンクに記事タイトルを入れる
- ga-analytics に Node.js 10 以上対応のプルリクを送る
- ブログメンティふりかえり8週目
- Serverless Meetup Tokyo 12 にて「サーバーレスなウェブフロントを実現する JAMstack」について発表をしました
- 初夏のJavaScript祭 in メンバーズキャリアにて「Gridsome で作る JAMstack なサーバーレス Web Front」の発表をしました
- 初夏のJavaScript祭にて発表した Gridsome のサンプルアプリ実装解説
- OSS-Friday 活動 - 2019年5月まとめ
- Git の設定をリポジトリごとに自動で使い分ける
- ブログメンティふりかえり10週目
- httpstat.us で、簡単 HTTP クライアントのテスト
- Nuxt.js で Vue コンポーネントの利用とコンポーネントの相互呼出しをする
- Shell の作業ディレクトリごとに自動で環境変数を設定する
- .gitignore は、生成サービス gitignore.io を使って作ろう!
- サーバレスな天気レポートの Slack ボット、「空鏡」
- OS や IDE 固有ファイルの .gitignore はどこにする?
- 「ドリルの王様 1,2年のたのしいプログラミング」、自然とプログラミング的思考が身につく問題集
- OSS-Friday 活動 - 2019年6月まとめ
- 「プレゼンドリル 伝えかた・話しかた」、勉強会、LT、イベント登壇のおともにしたいドリル
- Go_SaaS 三種の神器オンボーディングセミナー 1 〜東京〜 参加レポート
- Git で管理しているファイルの変更追跡を一時的に無視したい
- 勤怠を自動化する技術 LT Nightで、Web-NFC の PWA について LT しました
- CloudNative Days Tokyo 2019 にて「サーバレス・ネイティブ が お伝えする、フルサーバレス開発の魅力」の発表をしました
- Shiftup! JP_Getshifter Vol5! にて「Shifter + SSG の世界」について発表をしました
- Outlook で、自分のアドレスを常に Cc に入れる
- Netlify へ CLI デプロイで、CI/CD する
- Web API のモックサーバーとしても活躍、jsonbox.io
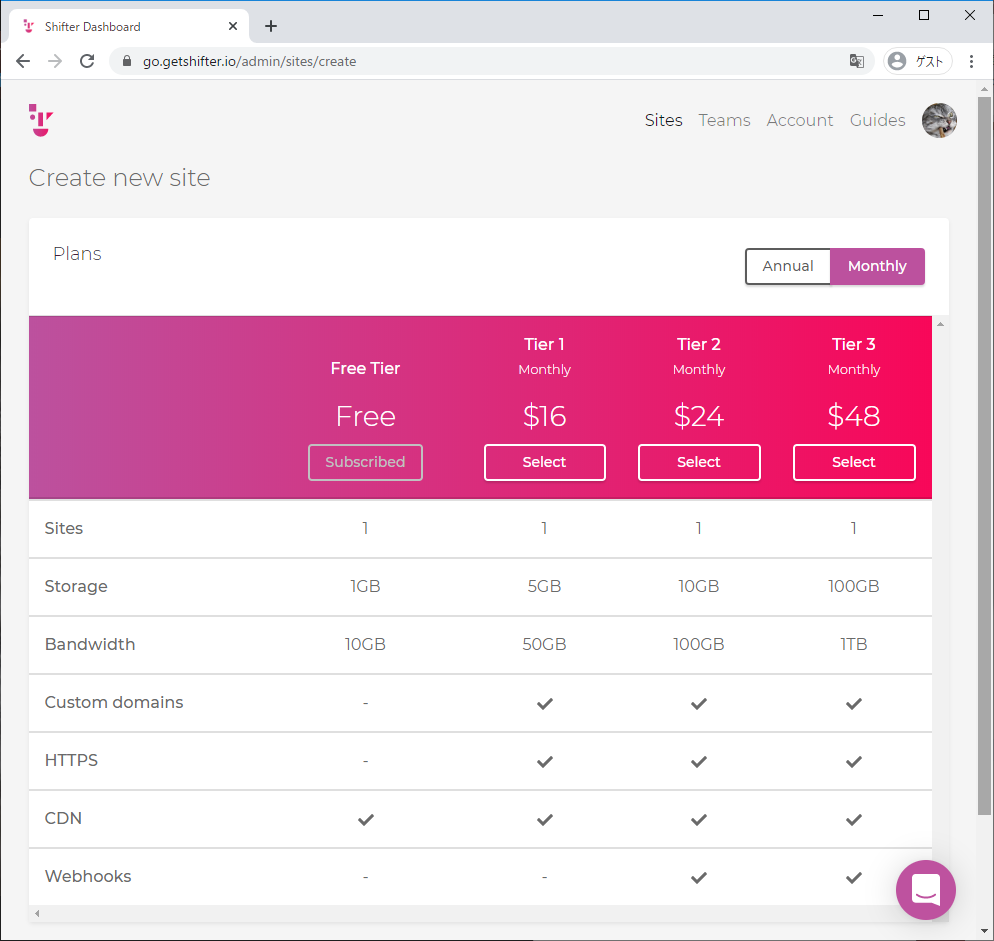
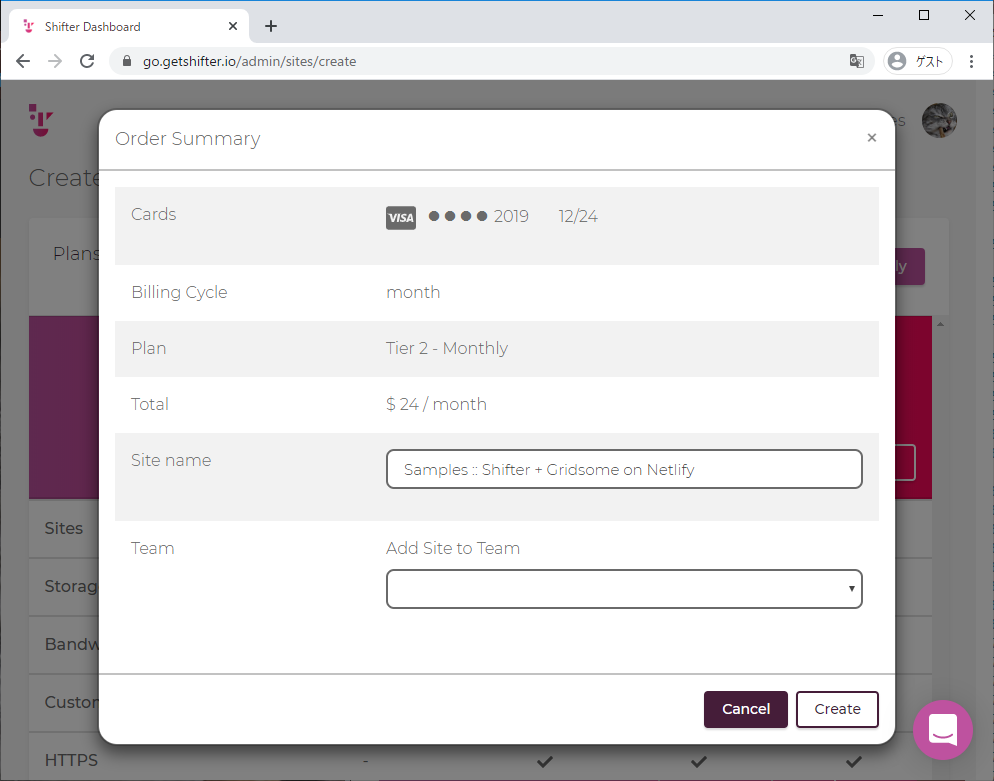
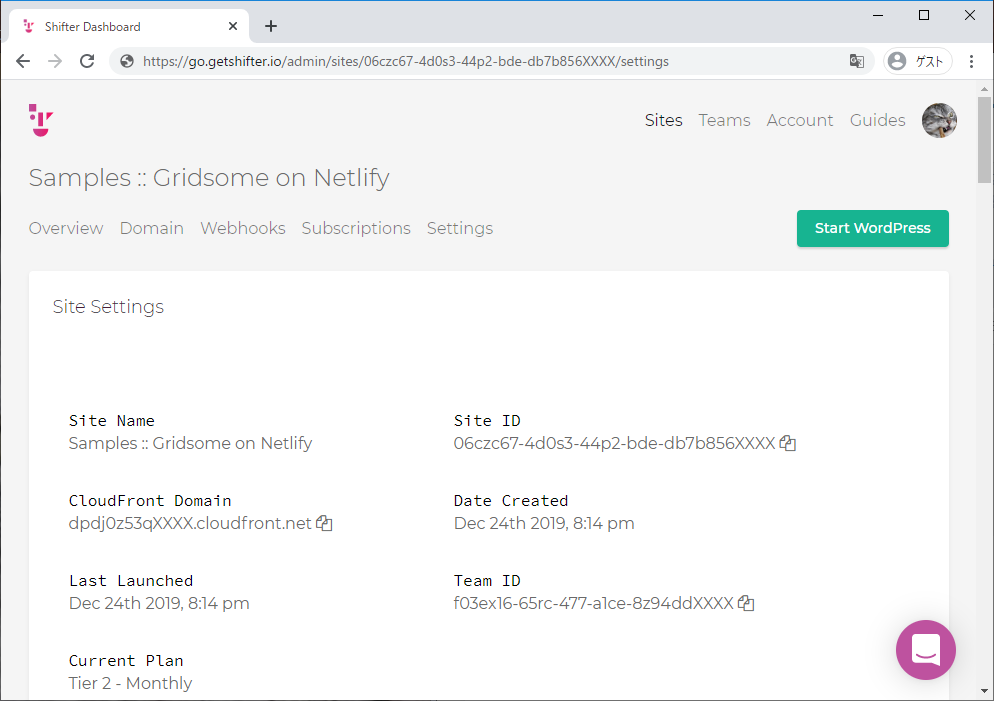
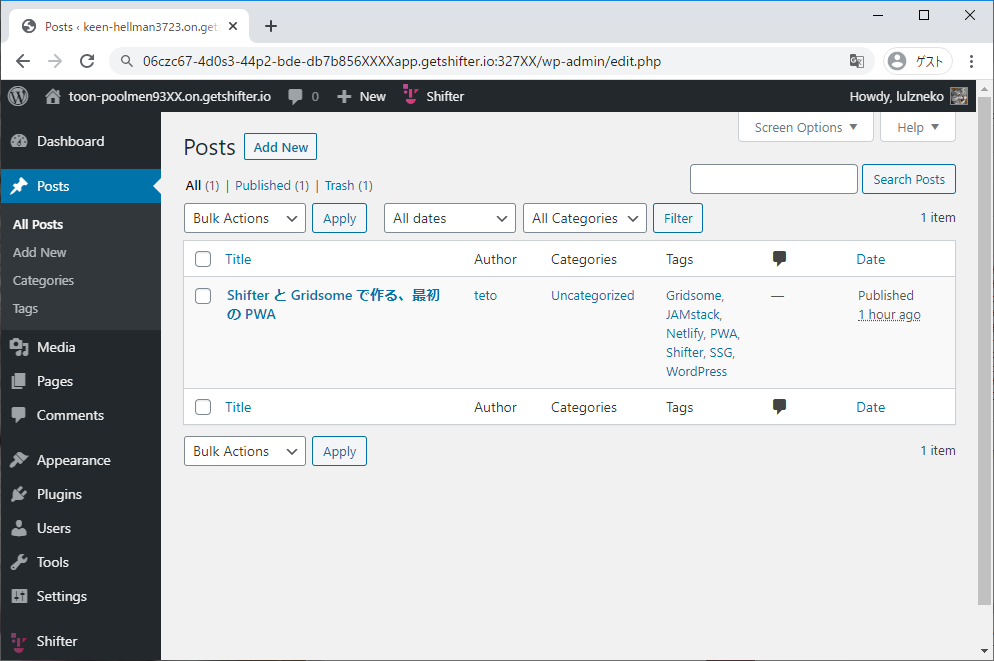
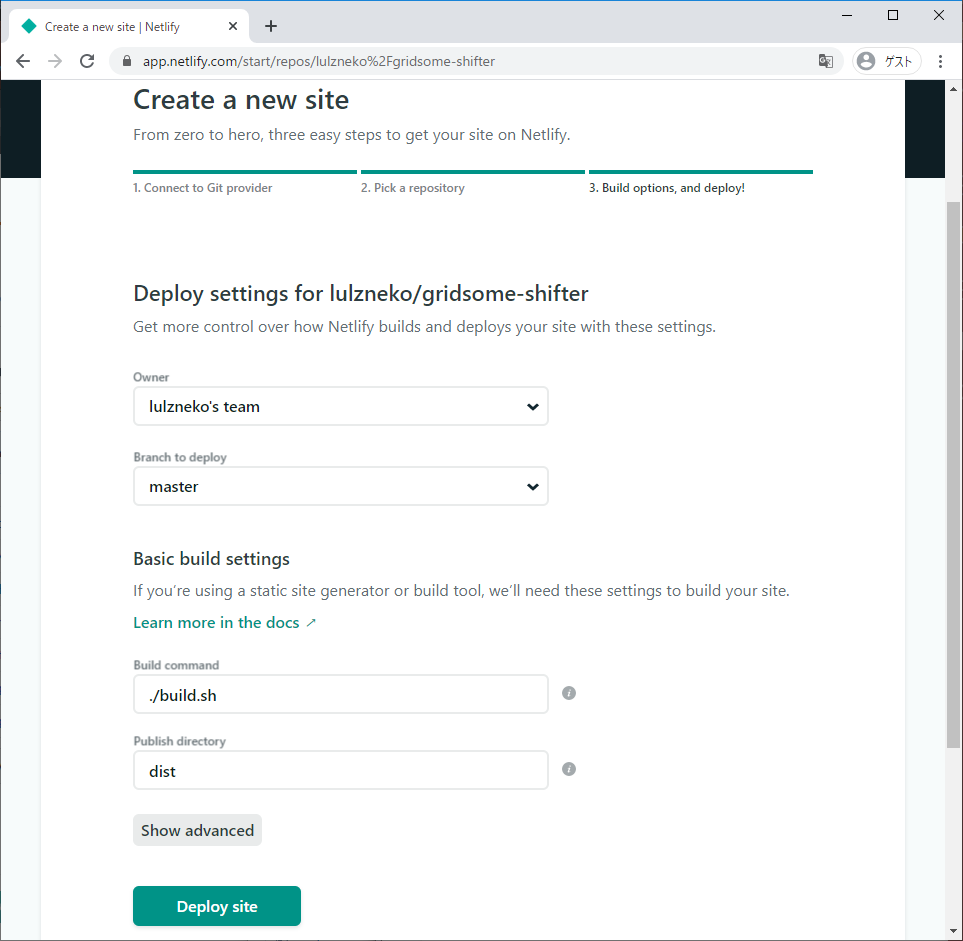
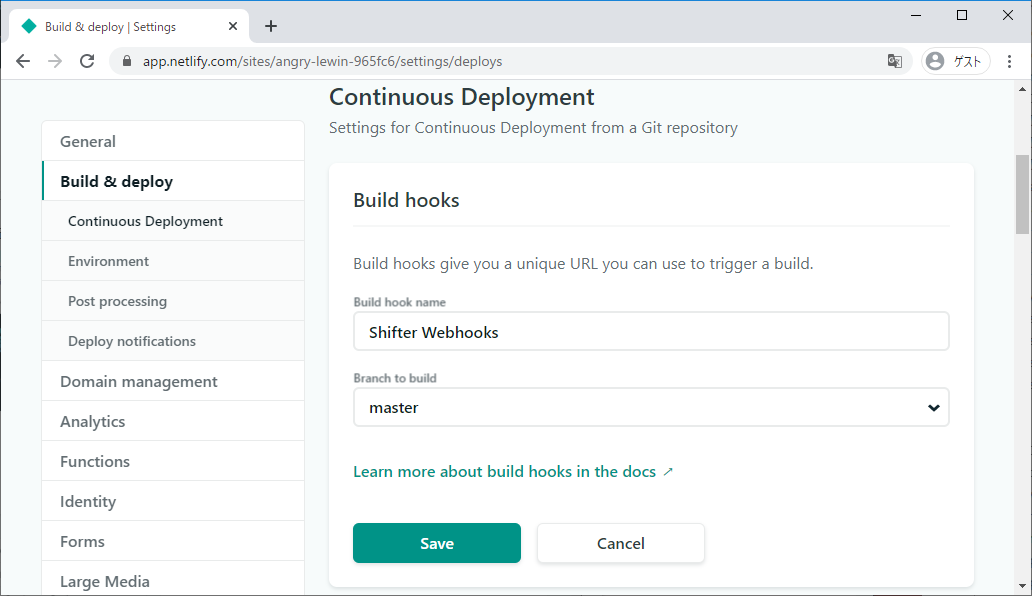
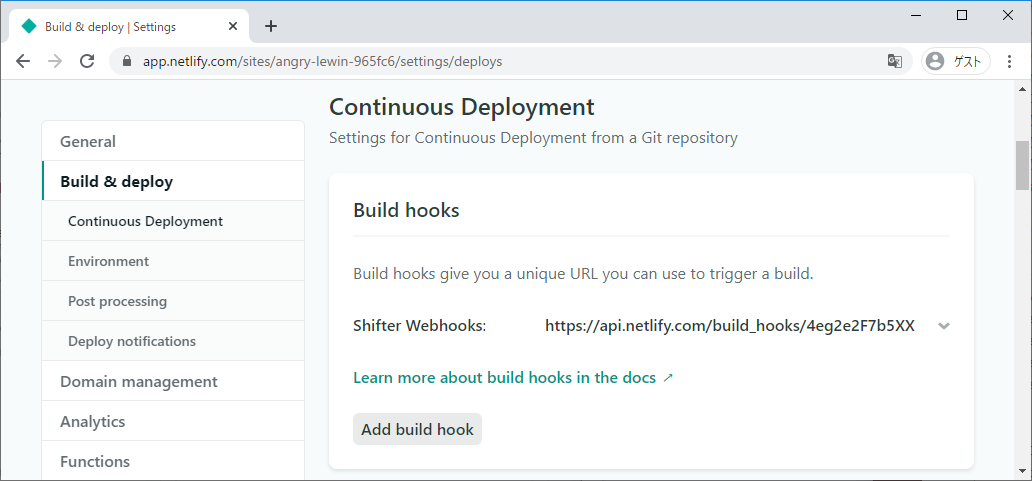
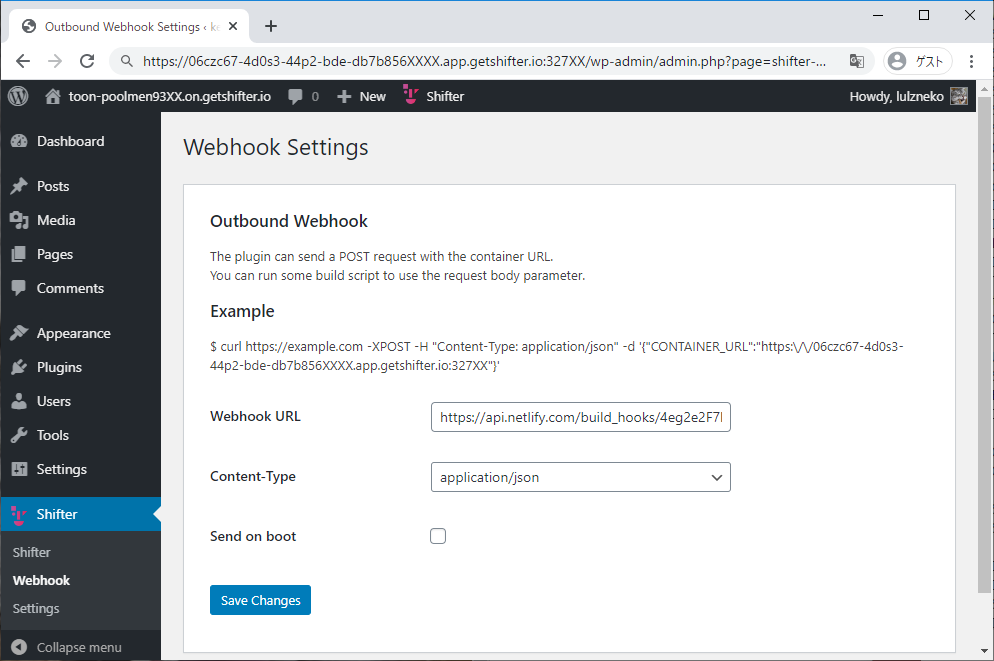
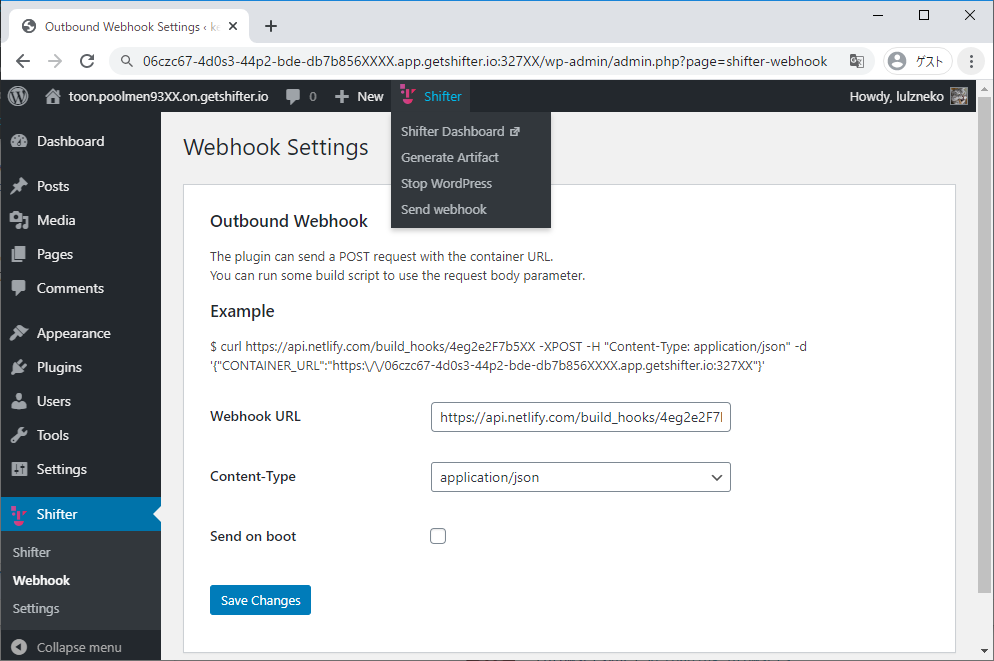
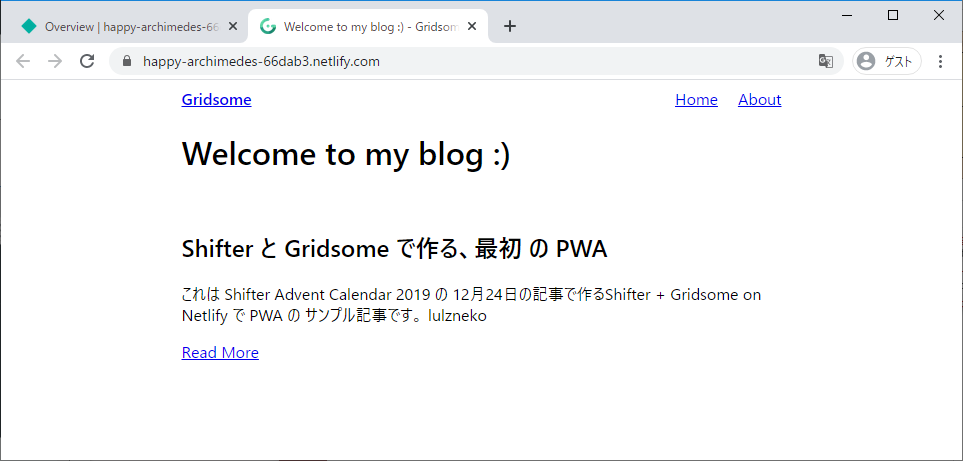
- Shifter Webhooks と Gridsome で作る、最初のウェブサイト on Netlify
去年は6本だったので大幅に増えましたが、4月~6月の間カック@技術ブロガー(@kakakakakku)さんに、ブログメンターへついていただいて3ヶ月間で 36本。つまり自力の9ヶ月では 25本でした。メンタリング前の 14本はよいとして、後半の6ヶ月で 11本はまずい。メンタリング前よりペースが落ちてる。。。
ちょうどそのころから、発表を月に2回したり、アプリ作りを伴う LT、Closed イベントへの対応、新規プロジェクトへの参画に、月3本の発表とかなり無茶なスケジュールを詰めてしまいブログに使う時間を次の発表準備に当ててしまったことが敗因です。発表直前まで資料に手入れするタイプなので、発表が続くとなおのこと発表資料へ注力。通常ブログはまだしも、発表しましたブログでサマリーを入れてないのはよくなかった。これは反省点で、来年はバランスをとって活動できるようにしたいです。
発表とブログの両輪があってこそ、技術やナレッジをしっかり伝えることができると思えばこそ、頑張りどころだと。
プルリク 17本
- grant-zietsman/validate-typescript- Fix error when this npm module user installs
- tea3/hexo-related-popular-posts - Support sub-path URL configuration with popular posts feature
- sfarthin/ga-analytics - Add a callback function to support Node.js v8 or later
- hexojs/hexo-theme-landscape - Include article title in tweets text when sharing with Twitter
- gridsome/gridsome-starter-default - Set default values in site description for more SEO friendly
- hexojs/hexo-theme-landscape - Remove Google+ shared link button because the Google+ service has ended
- zefman/gridsome-source-instagram - Fix typo in the usage configuration example
- hexojs/hexo-theme-landscape - Remove Google+ OGP header tags because the Google+ service has ended
- hexojs/hexo-theme-landscape - Set the banner image path as a configuration file (resolve 06)
- Readify/httpstatus - Respond object literals to JSON
- Readify/httpstatus - Add 103 Early Hints [RFC8297]
- Readify/httpstatus - Add 207 Multi-Status [RFC4918]
- Readify/httpstatus - Add 423 Locked [RFC4918]
- Readify/httpstatus - Add 506 Variant Also Negotiates [RFC2295]
- hexojs/hexo-browsersync - Introduce an option to change tag to inject Browsersync snippets
- hexojs/hexo-generator-category - Add the “order_by” option (resolve #6)
- hexojs/hexo-generator-tag - Add the “order_by” option (resolve #5)
今年は、はじめてプルリクを出すことに挑戦し 17本出すことができました。
もう少し貢献したかったですが、なかなかプルリクを送れそうなシーンを見つけられず難しかったです。引き続き貢献できる機会を狙ってプルリクを送りたいと思います。
アプリ開発 4本
| アプリ名 | イベント | 関連資料 |
|---|---|---|
| ミツカルヘアサロン💇 | CTO vs Hackers ハッカソン | ブログ/スライド |
| 📰NEWʑ Link | SPAJAM 2019 東京A予選 | ブログ/スライド |
| 空鏡 | ブログメンティー | ソース/ブログ |
| ツカエタルヒの記録 | 勤怠を自動化する技術 LT Night | ブログ/スライド |
アプリ作りの機会を得られたものの、リファクタリングや最終化ができてなくて「空鏡」以外は公開できてないのが残念なところ。
ちゃんと時間を作って仕上げたいです。
ハッカソン 2回
ハッカソンは開発者にとっての総合競技みたいなイメージを持っており、とても好きです。
今年は「CTO vs Hackers ハッカソン」と「SPAJAM 2019 東京A予選」の2つに参加しました。
「CTO vs Hackers ハッカソン」はアイデアソン含めて6時間と短時間のイベントでした。それも現場でチーム編成からなので、かなり緊張と不安がよぎるイベントでしたが、幸いにも「個人が提案する時代に向けたアプリ」という方向性でチームの思いが一致、そして深い理解と共感ができたことから良い開発が行えました。技術スタックも分散しかなりツイていたと思います。順位をつけるイベントではなかったので賞などはありませんでしたが、とても楽しめるハッカソンでした。
「SPAJAM 2019 東京A予選」は、2度目の SPAJAM 挑戦です。
チーム作りに時間をかけられず締め切り当日に Riotz 仲間のlopburny (ロップバーニー)(@lopburny)と相談して2人で出ました。さすがに2人は無謀と思っていましたが、チャンスを前に挑戦しないことは選べずハッカソンへ臨むことに。結果は残せませんでしたが、限られた時間の中で全てを出し切れたと思います。
なお徹夜ハッカソンのお供は#22 「Trello があるので眠れない」 | #omoiyarifm。意識を高く保つには良く(それ、別の意識や)、3回ぐらい聞いてましたw
Special Topics 2つ
カック@技術ブロガー(@kakakakakku)さんの、ブログメンター
4月~6月の3ヶ月間ブログのメンターについていただきました。
カックさんの資料やブログメンターの話はよく Twitter で見かけていて、機会があったらうけて見たいと思っていたのでスゴクありがたいです。
ブログのテーマだしから始まり、独自のブログシステムを使っていることからの改修点、ちょっと自分が情けないところとしてはタイポの指摘、記事の内容に関するレビューと方向性の指摘、そして何より技術者としての活動の幅を広げる話などをしてくれます。この期間で多くの勉強をさせていただき、ブログを書くことへの楽しさを知ることができたと思います。
一方でカックさんが一番おっしゃっていた「継続性」について、メンター終了後に続いてないのは大変申し訳なく思うとともに、自分を情けなくも思います。新しいことを始めたり、集中して取り組むことが得意なものの、継続は苦手。ブログメンティーの振り返り記事は書いていたのに、卒業を書いていなかったのは、その不安があったからです(あと直後の3発表+アプリ1本のスケジュールは入ってたから限界が見えてたのもある)。熱いうちに打てとも言いますが、熱いまま書いても性根は変わらないのであえて年末振り返りまで待つことにしましたが案の定。
ブログの項でも書きましたがスケジュールの不備が大きかったと思う(思いたい)ので、来年はバランスをとってブロギングをしっかりしていきたいです。
Serverless Operationshorike takahiro(@horike37)さんの、共創シフト
サーバーレスコミュニティのオーガナイザーを務めるhorike takahiro(@horike37)さん共創型開発へ参画させていただくことになりました。
horike takahiro(@horike37)さん資料
常々サーバーレスで開発するというのは開発サイクルを軽量に回すことができる、また H/W, OS, M/W などの運用面を最小化して開発に注力できることにメリットがあると感じていました。極端な話、開発面をサポートしアプリの仕様把握やメンテができるところまで一緒に行くことができたら、後はほぼ自分たちでできるのだろうなと。そうしたことを考えている中で私にできることは何かなと考えていました。
そんな折にサーバーレスをフルに活かす開発の手法としての共創型開発に興味と共感をもち、是非にと参加させていただきました。
こちらについては、どこかで発表や記事にしたいと思います。
※ サーバーレス開発支援の導入に興味ある方は Serverless Operationshorike takahiro(@horike37)へご連絡いただくか、私も取り次ぎしますので気軽にご相談ください。
Riotz.works が発足して、ほぼ3年。
1つのカンファレンスで発表することができて技術者としての活動の楽しさを感じ、そして活動を広げきました。
今年は、それが大きな活動につながった年だと言えるでしょう。
そこには多くの方々のつながりがあり、発表を聞いてくださり、ブログを読んでくださった皆さまのおかげです。
ありがとうございます!
引き続き、多くの技術やナレッジの情報を発信してまいります。
良かったところを伸ばし、反省点を見直して次の年へつなげられるよう頑張ります。
今後とも、よろしくお願いいたします。
よいお年を。